Latent Space Bayesian Optimization

Optimization is everywhere - in tuning machine learning models, industrial processes, and even in everyday decision-making. But what happens when the problem you want to optimize is a black box, expensive to evaluate, and has way too many parameters? That's where my master's thesis comes in: Latent Space Bayesian Optimization with Transfer Learning. Here's a deep dive into what I did, why it matters, and what I learned along the way.
The Problem: Black-Box Optimization in High Dimensions
Bayesian Optimization (BO) is a popular optimization method for expensive black-box functions, used in a variety of fields including hyperparameter optimization and industrial processes, up to moderate dimensions (10-20). The black box functions are sometimes over-parameterized which results in modeling redundant dimensions in high dimensional spaces. Optimization methods that focus on the most relevant dimensions find optimal solutions faster. Additionally, existing optimization data, e.g. from optimizing similar problems, can be used to further speed up the optimization process on the task of interest i.e. perform Transfer Learning. To warm start BO on the task at hand, it is of utmost importance to model data collected from similar tasks to transfer knowledge. In Transfer Learning BO, models which learn the underlying intrinsic function are essential. We propose a latent space model with Transfer Learning to, 1. learn a transformation from input space to latent space and 2. learn a common set of features from the learned latent space across multiple tasks to perform efficient Transfer Learning. Our model is empirically evaluated against state-of-the-art methods on synthetic benchmarks.
The Core Idea: Optimize Where It Matters
Latent Spaces
The key insight is that, even though your input space might be huge (dozens or hundreds of parameters), the intrinsic dimensionality is often much lower. In other words, only a few directions in parameter space actually affect your objective. If you can learn a transformation from the high-dimensional input to a low-dimensional latent space that captures the important variation, you can optimize much more efficiently.
Transfer Learning
If you've already solved similar optimization problems (maybe with different materials or settings), you should be able to transfer what you've learned. The challenge is to design a model that can leverage this metadata (past optimization runs) to "warm start" the new optimization, avoiding the cold start problem that plagues standard BO.
Joint Learning in Latent Space
My thesis proposes a method that jointly learns:
- A transformation from input space to latent space (either linear or nonlinear)
- A shared set of features (basis functions) across several tasks for transfer learning
The model is trained in two phases:
- Meta-training: Learn from metadata (previous tasks) to initialize the latent space and shared features.
- Target training: Adapt the model to the new task, fine-tuning both the latent space and the prediction model as new data comes in.
Model Architecture
I explored two main variants:
- Projection-ABLR: Uses a learnable linear projection from input to latent space, paired with Adaptive Bayesian Linear Regression (ABLR) for prediction.
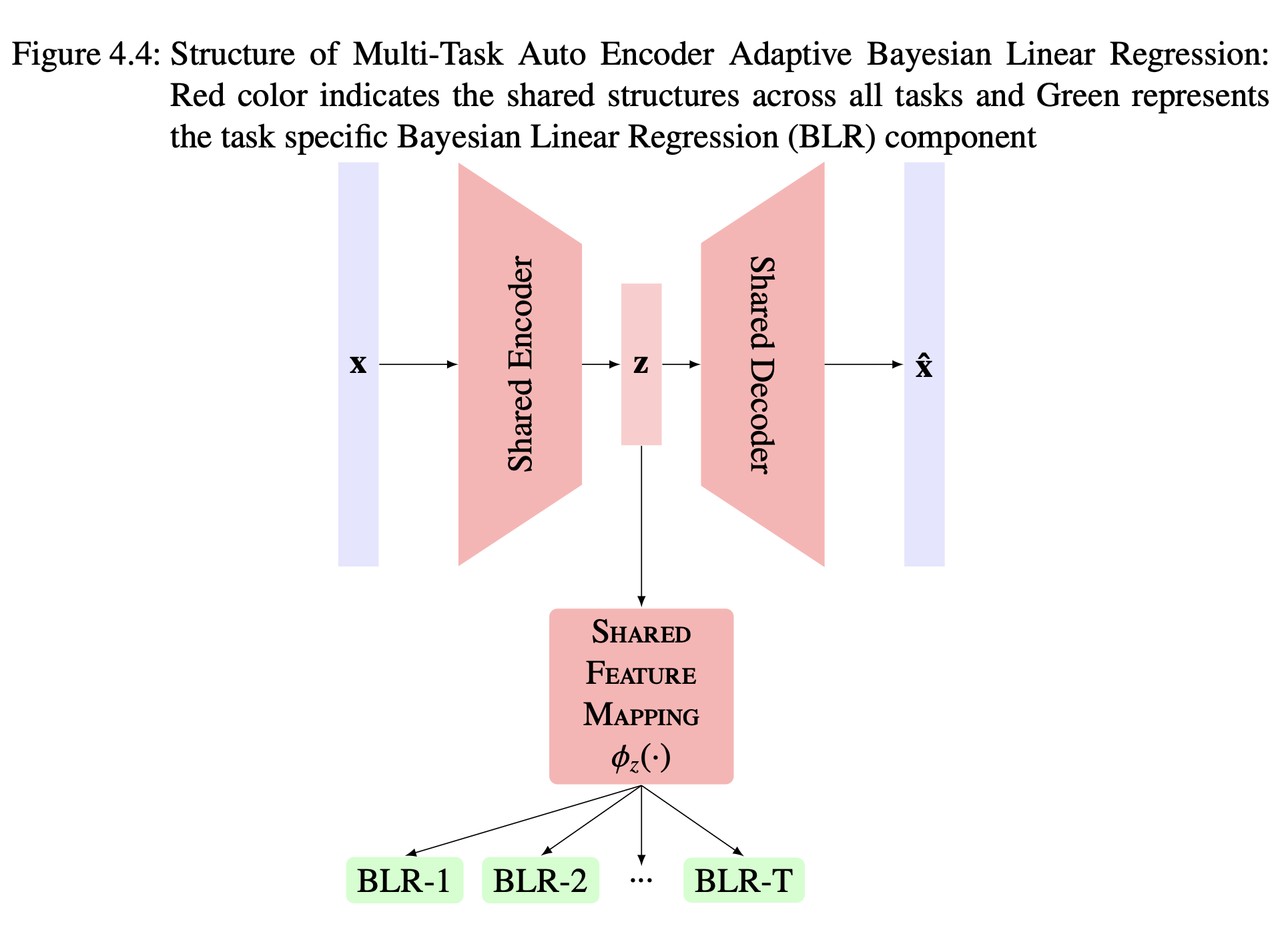
- AutoEncoder-ABLR: Uses an autoencoder (neural network) to learn a nonlinear mapping to latent space, again paired with ABLR.
Both models are trained to minimize a combination of negative log-likelihood (for prediction) and mean squared error (for reconstructing the input from the latent space). This joint loss ensures the latent space is predictive and reconstructive simulataneously.
Why ABLR?
Adaptive Bayesian Linear Regression is computationally efficient and scales well with the number of tasks and data points for transfer learning. It allows for a separate Bayesian regressor for each task but shares the feature mapping making it well suited for multi-task scenarios.
Experiments: Synthetic Benchmarks
To test the method, I used high-dimensional synthetic functions with known low intrinsic dimensionality:
- Quadratic function: Parameterized by a small set of variables, projected into higher dimensions.
- Rosenbrock function: A classic optimization benchmark, adapted for multi-task and high-dimensional settings.
I compared my models against state-of-the-art baselines:
- REMBO: Random Embeddings for Bayesian Optimization (no transfer learning)
- Multi-Task ABLR: Directly models in the input space with transfer learning
- VAE-BO: Variational Autoencoder-based Bayesian Optimization
Key Results
- Transfer learning helps: Models that leverage metadata start with lower regret (closer to the optimum) and converge faster, especially in the early iterations.
- Latent space optimization is efficient: By optimizing in the learned low-dimensional space, the search is much more effective than in the original high-dimensional space.
- Projection-ABLR outperforms: The linear projection model consistently achieved lower regret than baselines, especially when enough metadata was available.
- AutoEncoder-ABLR needs more data: Nonlinear models (autoencoders) can capture more complex relationships but require more data to avoid overfitting or saturation.
Challenges and Open Questions
- Estimating intrinsic dimensionality: Knowing how many latent dimensions to use is still an open problem. I tried cross-validation and meta-loss analysis, but the results were inconclusive. This remains a key challenge for future work.
- Scaling to real-world tasks: The method works well on synthetic benchmarks. Applying it to real industrial processes (like welding) is the next step.
- Negative transfer: If the metadata tasks are too different from the target, transfer learning can actually hurt performance. Designing robust ways to detect and avoid negative transfer is important.
Takeaways
- Joint learning works: Simultaneously learning the latent space and prediction model is more effective than sequential approaches, especially when data is scarce.
- Transfer learning is powerful: Leveraging past experience can dramatically speed up optimization in new tasks.
- Linear vs. nonlinear: Linear projections are surprisingly effective when the intrinsic structure is simple, but nonlinear mappings (autoencoders) are more flexible for complex tasks - if you have enough data.
Conclusion
My thesis shows that Latent Space Bayesian Optimization with Transfer Learning is a promising approach for high-dimensional, expensive black-box optimization. By learning where to search (latent space) and how to transfer knowledge from previous tasks, we can solve challenging optimization problems more efficiently.
If you're working on hyperparameter tuning, industrial process optimization, or any scenario where experiments are costly and you have some prior data, this approach could save you time, money, and frustration.